当我们在浏览器的地址栏输入 ,然后回车,回车这一瞬间到看到页面到底发生了什么呢?
整个流程如下:- 域名解析 -->
- 发起TCP的3次握手 -->
- 建立TCP连接后发起http请求 -->
- 服务器响应http请求,浏览器得到html代码 -->
- 浏览器解析html代码,并请求html代码中的资源(如js、css、图片等) -->
- 浏览器对页面进行渲染呈现给用户
以下就是上面过程的一一分析,我们就以Chrome浏览器为例:
域名解析
首先Chrome浏览器会解析 www.linux178.com 这个域名对应的IP地址。怎么解析到对应的IP地址?
Chrome浏览器会首先搜索浏览器自身的DNS缓存(缓存时间比较短,大概只有1分钟,且只能容纳1000条缓存)。如果浏览器自身缓存找不到则会查看系统的DNS缓存,如果找到且没有过期则停止搜索解析到此结束.而如果本机没有找到DNS缓存,则浏览器会发起一个DNS的系统调用,就会向本地配置的首选DNS服务器发起域名解析请求(通过的是UDP协议向DNS的53端口发起请求,这个请求是递归的请求,也就是运营商的DNS服务器必须得提供给我们该域名的IP地址),运营商的DNS服务器首先查找自身的缓存,找到对应的条目,且没有过期,则解析成功。如果没有找到对应的条目,则有运营商的DNS代我们的浏览器发起迭代DNS解析请求,它首先是会找根域的DNS的IP地址(这个DNS服务器都内置13台根域的DNS的IP地址),找打根域的DNS地址,就会向其发起请求(请问www.linux178.com这个域名的IP地址是多少啊?),根域发现这是一个顶级域com域的一个域名,于是就告诉运营商的DNS我不知道这个域名的IP地址,但是我知道com域的IP地址,你去找它去,于是运营商的DNS就得到了com域的IP地址,又向com域的IP地址发起了请求(请问www.linux178.com这个域名的IP地址是多少?),com域这台服务器告诉运营商的DNS我不知道www.linux178.com这个域名的IP地址,但是我知道linux178.com这个域的DNS地址,你去找它去,于是运营商的DNS又向linux178.com这个域名的DNS地址(这个一般就是由域名注册商提供的,像万网,新网等)发起请求(请问www.linux178.com这个域名的IP地址是多少?),这个时候linux178.com域的DNS服务器一查,诶,果真在我这里,于是就把找到的结果发送给运营商的DNS服务器,这个时候运营商的DNS服务器就拿到了www.linux178.com这个域名对应的IP地址,并返回给Windows系统内核,内核又把结果返回给浏览器,终于浏览器拿到了www.linux178.com对应的IP地址,该进行一步的动作了。发起TCP的3次握手
拿到域名对应的IP地址之后,User-Agent(一般是指浏览器)会以一个随机端口(1024< 端口 < 65535)向服务器的WEB程序(常用的有httpd,nginx等)80端口发起TCP的连接请求。这个连接请求(原始的http请求经过TCP/IP4层模型的层层封包)到达服务器端后(这中间通过各种路由设备,局域网内除外),进入到网卡,然后是进入到内核的TCP/IP协议栈(用于识别该连接请求,解封包,一层一层的剥开),还有可能要经过Netfilter防火墙(属于内核的模块)的过滤,最终到达WEB程序(本文就以Nginx为例),最终建立了TCP/IP的连接。
为什么HTTP协议要基于TCP来实现?
TCP是一个端到端的可靠的面向连接的协议,所以HTTP基于传输层TCP协议不用担心数据的传输的各种问题。
建立TCP连接后发起http请求
进过TCP3次握手之后,浏览器发起了http的请求,使用的http的方法 GET 方法,请求的URL是 / ,协议是HTTP/1.0

下面是第12号包的详细内容:

以上的报文是HTTP请求报文。
那么HTTP请求报文和响应报文会是什么格式呢?
个HTTP请求报文由请求行(request line),请求头部(header),空行和请求数据4个部分组成,下图给出了请求报文的一般格式。
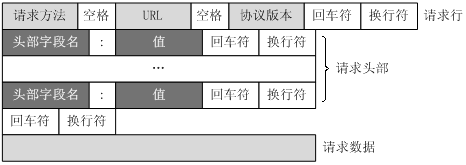
请求行
请求行由请求方法字段、URL字段和HTTP协议版本字段3个字段组成,它们用空格分隔。例如,GET /index.html HTTP/1.1。
HTTP协议的请求方法有GET、POST、HEAD、PUT、DELETE、OPTIONS、TRACE、CONNECT。这里介绍最常用的GET方法和POST方法。- GET:当客户端要从服务器中读取文档时,使用GET方法。GET方法要求服务器将URL定位的资源放在响应报文的数据部分,回送给客户端。使用GET方法时,请求参数和对应的值附加在URL后面,利用一个问号(“?”)代表URL的结尾与请求参数的开始,传递参数长度受限制。例如,/index.jsp?id=100&op=bind。
- POST:当客户端给服务器提供信息较多时可以使用POST方法。POST方法将请求参数封装在HTTP请求数据中,以名称/值的形式出现,可以传输大量数据。
请求头部
请求头部由关键字/值对组成,每行一对,关键字和值用英文冒号“:”分隔。请求头部通知服务器有关于客户端请求的信息,典型的请求头有:User-Agent:产生请求的浏览器类型。Accept:客户端可识别的内容类型列表。Host:请求的主机名,允许多个域名同处一个IP地址,即虚拟主机。空行
最后一个请求头之后是一个空行,发送回车符和换行符,通知服务器以下不再有请求头。请求数据
请求数据不在GET方法中使用,而是在POST方法中使用。POST方法适用于需要客户填写表单的场合。与请求数据相关的最常使用的请求头是Content-Type和Content-Length。
那么起始行中的请求方法有哪些种呢?
GET: 完整请求一个资源 (常用)
HEAD: 仅请求响应首部POST:提交表单 (常用)PUT: 上传DELETE:删除那什么是URL、URI、URN?
URI Uniform Resource Identifier 统一资源标识符
URL Uniform Resource Locator 统一资源定位符 格式如下: scheme://[username:password@]HOST:port/path/to/source Uniform Resource Name 统一资源名称URL和URN 都属于 URI为了方便就把URL和URI暂时都通指一个东西请求的协议有哪些种?
有以下几种:http/0.9: statelesshttp/1.0: MIME, keep-alive (保持连接), 缓存http/1.1: 更多的请求方法,更精细的缓存控制,持久连接(persistent connection) 比较常用下面是Chrome发起的http请求报文头部信息

其中
Accept 就是告诉服务器端,我接受那些MIME类型Accept-Encoding 这个看起来是接受那些压缩方式的文件Accept-Lanague 告诉服务器能够发送哪些语言 Connection 告诉服务器支持keep-alive特性Cookie 每次请求时都会携带上Cookie以方便服务器端识别是否是同一个客户端Host 用来标识请求服务器上的那个虚拟主机,比如Nginx里面可以定义很多个虚拟主机 那这里就是用来标识要访问那个虚拟主机。User-Agent 用户代理,一般情况是浏览器,也有其他类型,如:wget curl 搜索引擎的蜘蛛等 条件请求首部:If-Modified-Since 是浏览器向服务器端询问某个资源文件如果自从什么时间修改过,那么重新发给我,这样就保证服务器端资源 文件更新时,浏览器再次去请求,而不是使用缓存中的文件安全请求首部:Authorization: 客户端提供给服务器的认证信息;服务器端响应http请求,浏览器得到html代码
服务器端WEB程序接收到http请求以后,就开始处理该请求,处理之后就返回给浏览器html文件。

第32号包 是服务器返回给客户端http响应包(200 ok 响应的MIME类型是text/html),代表这一次客户端发起的http请求已成功响应。200 代表是的 响应成功的状态码,还有其他的状态码如下:
1xx: 信息性状态码 100, 1012xx: 成功状态码 200:OK3xx: 重定向状态码 301: 永久重定向, Location响应首部的值仍为当前URL,因此为隐藏重定向; 302: 临时重定向,显式重定向, Location响应首部的值为新的URL 304:Not Modified 未修改,比如本地缓存的资源文件和服务器上比较时,发现并没有修改,服务器返回一个304状态码, 告诉浏览器,你不用请求该资源,直接使用本地的资源即可。4xx: 客户端错误状态码 404: Not Found 请求的URL资源并不存在5xx: 服务器端错误状态码 500: Internal Server Error 服务器内部错误 502: Bad Gateway 前面代理服务器联系不到后端的服务器时出现 504:Gateway Timeout 这个是代理能联系到后端的服务器,但是后端的服务器在规定的时间内没有给代理服务器响应浏览器解析html代码,并请求html代码中的资源
浏览器拿到index.html文件后,就开始解析其中的html代码,遇到js/css/image等静态资源时,就向服务器端去请求下载(会使用多线程下载,每个浏览器的线程数不一样),这个时候就用上keep-alive特性了,建立一次HTTP连接,可以请求多个资源。
浏览器在请求静态资源时(在未过期的情况下),向服务器端发起一个http请求(询问自从上一次修改时间到现在有没有对资源进行修改),如果服务器端返回304状态码(告诉浏览器服务器端没有修改),那么浏览器会直接读取本地的该资源的缓存文件。

浏览器对页面进行渲染呈现给用户
最后,浏览器利用自己内部的工作机制,把请求到的静态资源和html代码进行渲染,渲染之后呈现给用户。